Spurious correlations
*apologies for pay-walled links ahead*
I was first confronted by spurious correlations in language and culture during the EVOLANG 10 conference in Vienna in 2014, where I think I saw a poster on the relationship between tense marking and economic behaviour. If I remember correctly, this poster build on the famous findings of Keith Chen, who published a paper in 2013 on the relationship between obligatory future tense marking and various types of social and economical decisions people take.
The paper was very controversial before it was even published, with posts on Language Log (see links at bottom of the page for more posts) a reply on Language Log by Keith Chen and a variety of media coverage that can be found here and here and here and here.
Chen found that languages lacking a distinct future tense: "save more, retire with more wealth, smoke less, practice safer sex, and are less obese" (abstract). He explains his findings as follows "[...] being required to speak in a distinct way about future events leads speakers to take fewer future-oriented actions. This hypothesis arises naturally if grammatically separating the future and the present leads speakers to disassociate the future from the present. This would make the future feel more distant, and since saving involves current costs for future rewards, would make saving harder. On the other hand, some languages grammatically equate the present and future. Those speakers would be more willing to save for a future which appears closer. Put another way, I ask whether a habit of speech which disassociates the future from the present, can cause people to devalue future rewards." (section 1).
At EVOLANG, I felt completely flabbergasted at these findings. How could such complex individual decisions, including on how much to save for later life, dietary habits, sex habits, and smoking habits, be related to a tiny aspect of the language that one speaks? It seemed completely unrealistic to me, although Chen (2013) goes through some efforts to explain the mechanisms through which this connection would work.

Then in 2015, the Chen (2013) study was partly refuted by a follow-up study by Seán Roberts, James Winters, and Keith Chen. Lead author Seán Roberts wrote two blog post about their study, found here and here. They point out several criticisms of Chen's (2013) paper, but focus on whether the correlation between less savings and a distinct future tense remained when controlling for the historical relatedness of the languages included in the study. As it turned out, the correlation was no longer significant when the control was included. Their point is that both language and culture have to be considered in light of history: languages are likely to inherit a particular way of marking future tense from their ancestors, and populations are likely to have economic and dietary habits similar to the populations from which they descend. Once this genealogical signal was taking into account, the relationship between the predisposition to save less money and having obligatory future marking became insignificant.
(BTW, The person who is aiming to shed more light on this is Cole Robertson, who wrote a follow-up post on a new study on the topic op future tense and economic decision taking.)
The problem I talk about here is not new. Seán Roberts and James Winters wrote an article in 2013 warning against spurious correlations between cultural traits - correlations between traits that are very likely accidents of history as there is no functional mechanism that could explain the association between the two types of behaviour. They illustrate the existence of spurious correlations by showing that these exist between morphological complexity and having a siesta or not, and between the presence of acacia trees and tone languages within countries. The problems they identify include the following:
1. Galton's problem: the need to control for historical relatedness and diffusional associations in order not to overestimate the number of independent datapoints;
2. Distance from data: In many cases, the data on a language has been collected by one individual and this data is subsequently categorised into (sometimes coarse) variables, creating a distance between the dataset and reality;
3. Inverse sample size problem: given that culture data is often incomplete, complex, and based on inconsistent data, the noise-to-signal ratio increases rather than decreases in larger datasets.
They warn that correlational studies should bear in mind a realistic hypothesised mechanism for the correlation, and should attempt to control for alternative explanations, especially those relating to diffusion and historical descent. Here are some cool pictures bringing across this point, and there is far more on spurious correlations on Replicated Typo.

However, the story does not end here. To my surprise, their are A LOT of papers that report correlations between aspects of language and sociological aspects of culture that seem far-fetched, and clearly they have not read Roberts & Winters (2013). I am not talking about the overview provided by Ladd et al. (2014), blogpost here, who present a review of studies that look at correlations between languages and non-linguistic forces acting on language, including variables such as the amount of second-language speakers and the type of climate. The kind of demographics that they cover in their review make much more sense to me: population size, for instance, should be expected to have an effect on certain aspects of language as it makes a huge difference whether you speak your language within a village of 100 people, or within a state with 100 million people.
I am talking about studies like the following. In 2013, Santacreu-Vasut and colleagues published a paper entitled "Do female/male distinctions in language matter? Evidence from gender political quotas" in Applied Economics Letters. This paper investigates the correlation between an index of gender variables from the World Atlas of Language Structures and the presence of a legislated quota of female members in the lower house of parliament. They find that such a correlation exists, in their words: "Countries with a higher emphasis of female/male distinctions in their dominant language (higher GII) are therefore more likely to regulate women's political participation." (p. 497). I am not even going to get started on the gender index they used, which does not adequately measure whether languages make a male/female distinction in their grammar - I am just going to say that the claim is very likely to be a spurious one. The data on gender quotas indicates that most European countries as well as many sub-Saharan African countries have gender quotas - both areas are 'gender hotbeds' (Nichols 1992: 132), as gender is both areally and phylogenetically stable in these places. So the national languages of these countries are probably driving the effect found by Santacreu-Vasut et al., making the finding an historical accident rather than a true link between gender and legalised political engagement of women.
Unlike the data on propensity to save money used by Chen (2013), the data is collected on a country level, taking the 'most spoken' language as the appropriate variable to associate with country-level variables on political participation, the Human Development Index, and the number of years since women were first allowed to run for election. I have a huge problem with this. Most countries harbor speakers of tens or hundreds of different languages (remember the map on number of languages per countries?), although most have a limited set of national languages. It is completely inappropriate to set any national language to be THE language associated with country level demographics and propose their correlational findings to be in line with theory on language shaping cognition.

Things would not be so bad if, as Roberts & Winters (2013) say in their paper: "Since some of these studies are receiving media attention without a widespread understanding of the complexities of the issue, there is a risk that poorly controlled studies could affect policy." Santacreu-Vasut et al. (2013) has been cited over 20 times so far. I simply do not have the guts to look at detail to all of these, but some of them are:
Lucas van der Velde et al. (2015) 'Language and (the estimates of) the gender wage gap', from the conclusion: "We hypothesized that in countries where language has a more marked distinction between genders, differences in labor market outcomes will be larger. [...] The results robustly confirm the hypothesis." and explicitly on policy: "From a policy perspective, the major message of our study is that gender wage gap may be driven by some deep societal features stemming from such basic social codes as language. This suggests that if reducing GWG [gender wage gap, AV] was a policy objective, education on gender equality is needed already at early stages of education, when language characteristics are absorbed by children and translated into societal norms."
Hicks et al. (2015) 'Does mother tongue make for women's work? Linguistics, household labor, and gender identity'; from the abstract: "We use a novel approach relying on linguistic variation and document that households with individuals whose native language emphasizes gender in its grammatical structure are significantly more likely to allocate household tasks on the basis of sex and to do so more intensively."
Davis and Reynolds (2016) 'Gendered language and the educational gender gap'
Shoham et al. (2017) 'Encouraging environmental sustainability through gender: A micro-foundational approach using linguistic gender marking'
Malul et al. (2016) 'Linguistic gender marking gap and female staffing at MNC’s'
Seán Roberts also commented on an earlier paper by some of the authors featured above here. At the bottom of this post he says: "To put it cynically, it’s as if gender inequality is only due to humans being slaves to their language, rather than centuries of active patriarchal societies. The hypothesis doesn’t seem to have a good reason why distinctions in gender should disfavour women over men. Perhaps most disturbing is the authors’ clear appeal for these findings to be used in policy"
Indeed, this is scary stuff.
A more popular paper, albeit with perhaps less dire consequences on policy is Kashima and Kashima (1998), who find a positive correlation between pronoun drop, a grammatical phenomenon where pronouns can be left out of otherwise well-formed sentences, and collectivism, a tendency for society to look after in-group members. As was the case for Santacreu-Vasut et al. (2013), the unit of analysis is the country, with the national language taken to supply information about pronoun drop. This paper has been cited over 300 times and seems to be in high standing in cross-cultural psychological research, as it is being cited in handbooks and otherwise mostly in papers that do not pertain to this exact hypothesis, suggesting it's results are taken as a given. There is also a follow up by the same authors, Kashima and Kashima (2003), including a larger set variables on economy, climate, and geography, and an erratum to the 1998 article from 2005.

The established nature of these types of papers is underlined by the fact that the attention to potential spurious correlations is not confined to specialist journals such as Journal of Cross-Cultural Psychology and Applied Economics Letters. Science published a paper in 2014 by Talhelm et al. entitled 'Large-Scale psychological differences within China explained by rice versus wheat agriculture'. From the abstract: "We tested 1162 Han Chinese participants in six sites and found that rice-growing southern China is more interdependent and holistic-thinking than the wheat-growing north." See a popular write-up of the paper here and here.
Luckily, we can count on the absolute hero Seán Roberts to provide a commentary. See here for a blog write-up. Roberts shows that it is very likely that at least part of the correlation reported by Talhelm et al. can be explained by linguistic history, again showing the need for a control for cultural contact and genealogy.
I am sure there are more papers in this vein - please comment if you know of any! I am of half a mind to track them all down, get their data, and show that most if not all of these relations disappear when controlling for genealogical descent and/or diffusion. On the other hand, clearly this would be a waste of time as the premise of most of these papers is that the national or 'most used' language of a country can be of influence on population-level findings on social and economic behaviour, a premise which I think is inherently flawed. The mechanism behind such relationships is simply unfathomable, despite the efforts taken by the authors of these papers to demonstrate the contrary. I am thinking of the level of multilingualism in most countries, let alone the amount of different communities with different psychological and economic behaviours.
Turns out that the paper on rice and wheat agriculture by Talhelm et al. (2014) is in fact an improvement on at least this issue, as it looks in detail at agricultural practices and psychological measures within a set of provinces in one country, China. However, it still doesn't account for the contingencies that arise when comparing communities that are both closely related and in close contact.
There really is no longer any excuse for not incorporating information on geographical distance and genealogical descent in cross-linguistic and cross-cultural analysis. There are reference trees available for all language families in several typological and reference databases (Glottolog, Ethnologue, AUTOTYPE, WALS) - the awesome Dan Dediu has made this extremely easy for you as explained here, as well as Bayesian posterior samples of phylogenetic trees for over 10 language families. On Glottolog, latitude and longitude of the location of a speaker populations are freely available. D-PLACE has cultural variables for many societies around the world linked to language and various phylogenetic trees. All the people that have worked on potentially spurious correlations in language and culture know how to use statistics, well great! - you can use multilevel models and regressions that correct for genealogical relatedness and geographic distance and do things the way you should be doing things.

EDIT: Seán Roberts alerted me to the newly published The Palgrave Handbook of Economics and Language, with a paper by Nigel Fabb that is critical of these studies entitled "Linguistic Theory, Linguistic Diversity and Whorfian Economics". His main critiques are 1) the linguistic data is simplified to such an extent that it may no longer represent linguistic facts; and 2) the studies do not present a demonstration of causation despite their claims, and need to present a far more rigourous case both in theory and in experimentation. I am really happy this critical paper was published in a venue which will surely be read by economists, yay!
Selected references
Chen, M. K. (2013). The Effect of Language on Economic Behavior: Evidence from Savings Rates, Health Behaviors, and Retirement Assets. American Economic Review 103.690–731.
Kashima, E. S. & Kashima, Y. (1998). Culture and language: The case of cultural dimensions and personal pronoun use. Journal of Cross-Cultural Psychology 29.461-486.
Kashima, Y. & Kashima, E. S. (2003). Individualism, GNP, climate, and pronoun drop: Is individualsm determined by affluence and climate, or does language play a role? Journal of Cross-Cultural Psychology 34.125-134.
Ladd, D. R., Roberts, S. G. & Dediu, D. (2014). Correlational studies in typological and historical linguistics. Annual Review of Linguistics 1.221-41.
Nichols, J. (1992). Linguistic diversity in space and time. Chicago: University of Chicago Press.
Roberts, S. G. & Winters, J. (2013). Linguistic diversity and traffic accidents: Lessons from statistical studies of cultural traits. PloS One 8.e70902.
Roberts, S. G., Winters, J. & Chen, K. (2015). Future tense and economic decisions: Controlling for cultural evolution. PloS One 10.e0132145.
Santacreu-Vasut, E., Shoham, A. & Gay, V. (2013). Do female/male distinctions in language matter? Evidence from gender political quotas. Applied Economics Letters 20.495-98.
I was first confronted by spurious correlations in language and culture during the EVOLANG 10 conference in Vienna in 2014, where I think I saw a poster on the relationship between tense marking and economic behaviour. If I remember correctly, this poster build on the famous findings of Keith Chen, who published a paper in 2013 on the relationship between obligatory future tense marking and various types of social and economical decisions people take.
The paper was very controversial before it was even published, with posts on Language Log (see links at bottom of the page for more posts) a reply on Language Log by Keith Chen and a variety of media coverage that can be found here and here and here and here.
Chen found that languages lacking a distinct future tense: "save more, retire with more wealth, smoke less, practice safer sex, and are less obese" (abstract). He explains his findings as follows "[...] being required to speak in a distinct way about future events leads speakers to take fewer future-oriented actions. This hypothesis arises naturally if grammatically separating the future and the present leads speakers to disassociate the future from the present. This would make the future feel more distant, and since saving involves current costs for future rewards, would make saving harder. On the other hand, some languages grammatically equate the present and future. Those speakers would be more willing to save for a future which appears closer. Put another way, I ask whether a habit of speech which disassociates the future from the present, can cause people to devalue future rewards." (section 1).
At EVOLANG, I felt completely flabbergasted at these findings. How could such complex individual decisions, including on how much to save for later life, dietary habits, sex habits, and smoking habits, be related to a tiny aspect of the language that one speaks? It seemed completely unrealistic to me, although Chen (2013) goes through some efforts to explain the mechanisms through which this connection would work.

Save, but only if you speak German or another future-less language
Then in 2015, the Chen (2013) study was partly refuted by a follow-up study by Seán Roberts, James Winters, and Keith Chen. Lead author Seán Roberts wrote two blog post about their study, found here and here. They point out several criticisms of Chen's (2013) paper, but focus on whether the correlation between less savings and a distinct future tense remained when controlling for the historical relatedness of the languages included in the study. As it turned out, the correlation was no longer significant when the control was included. Their point is that both language and culture have to be considered in light of history: languages are likely to inherit a particular way of marking future tense from their ancestors, and populations are likely to have economic and dietary habits similar to the populations from which they descend. Once this genealogical signal was taking into account, the relationship between the predisposition to save less money and having obligatory future marking became insignificant.
(BTW, The person who is aiming to shed more light on this is Cole Robertson, who wrote a follow-up post on a new study on the topic op future tense and economic decision taking.)
The problem I talk about here is not new. Seán Roberts and James Winters wrote an article in 2013 warning against spurious correlations between cultural traits - correlations between traits that are very likely accidents of history as there is no functional mechanism that could explain the association between the two types of behaviour. They illustrate the existence of spurious correlations by showing that these exist between morphological complexity and having a siesta or not, and between the presence of acacia trees and tone languages within countries. The problems they identify include the following:
1. Galton's problem: the need to control for historical relatedness and diffusional associations in order not to overestimate the number of independent datapoints;
2. Distance from data: In many cases, the data on a language has been collected by one individual and this data is subsequently categorised into (sometimes coarse) variables, creating a distance between the dataset and reality;
3. Inverse sample size problem: given that culture data is often incomplete, complex, and based on inconsistent data, the noise-to-signal ratio increases rather than decreases in larger datasets.
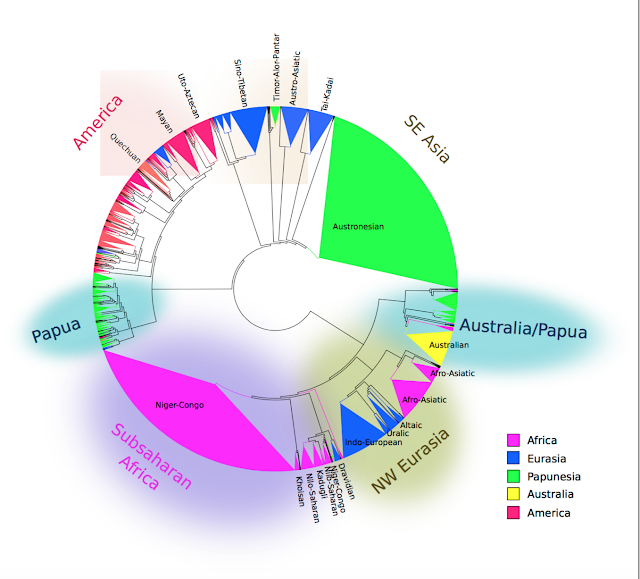
They warn that correlational studies should bear in mind a realistic hypothesised mechanism for the correlation, and should attempt to control for alternative explanations, especially those relating to diffusion and historical descent. Here are some cool pictures bringing across this point, and there is far more on spurious correlations on Replicated Typo.

Use trees!
However, the story does not end here. To my surprise, their are A LOT of papers that report correlations between aspects of language and sociological aspects of culture that seem far-fetched, and clearly they have not read Roberts & Winters (2013). I am not talking about the overview provided by Ladd et al. (2014), blogpost here, who present a review of studies that look at correlations between languages and non-linguistic forces acting on language, including variables such as the amount of second-language speakers and the type of climate. The kind of demographics that they cover in their review make much more sense to me: population size, for instance, should be expected to have an effect on certain aspects of language as it makes a huge difference whether you speak your language within a village of 100 people, or within a state with 100 million people.
I am talking about studies like the following. In 2013, Santacreu-Vasut and colleagues published a paper entitled "Do female/male distinctions in language matter? Evidence from gender political quotas" in Applied Economics Letters. This paper investigates the correlation between an index of gender variables from the World Atlas of Language Structures and the presence of a legislated quota of female members in the lower house of parliament. They find that such a correlation exists, in their words: "Countries with a higher emphasis of female/male distinctions in their dominant language (higher GII) are therefore more likely to regulate women's political participation." (p. 497). I am not even going to get started on the gender index they used, which does not adequately measure whether languages make a male/female distinction in their grammar - I am just going to say that the claim is very likely to be a spurious one. The data on gender quotas indicates that most European countries as well as many sub-Saharan African countries have gender quotas - both areas are 'gender hotbeds' (Nichols 1992: 132), as gender is both areally and phylogenetically stable in these places. So the national languages of these countries are probably driving the effect found by Santacreu-Vasut et al., making the finding an historical accident rather than a true link between gender and legalised political engagement of women.
Unlike the data on propensity to save money used by Chen (2013), the data is collected on a country level, taking the 'most spoken' language as the appropriate variable to associate with country-level variables on political participation, the Human Development Index, and the number of years since women were first allowed to run for election. I have a huge problem with this. Most countries harbor speakers of tens or hundreds of different languages (remember the map on number of languages per countries?), although most have a limited set of national languages. It is completely inappropriate to set any national language to be THE language associated with country level demographics and propose their correlational findings to be in line with theory on language shaping cognition.

Non-gray countries have some form of legislated candidate quotas, from http://www.quotaproject.org
Things would not be so bad if, as Roberts & Winters (2013) say in their paper: "Since some of these studies are receiving media attention without a widespread understanding of the complexities of the issue, there is a risk that poorly controlled studies could affect policy." Santacreu-Vasut et al. (2013) has been cited over 20 times so far. I simply do not have the guts to look at detail to all of these, but some of them are:
Lucas van der Velde et al. (2015) 'Language and (the estimates of) the gender wage gap', from the conclusion: "We hypothesized that in countries where language has a more marked distinction between genders, differences in labor market outcomes will be larger. [...] The results robustly confirm the hypothesis." and explicitly on policy: "From a policy perspective, the major message of our study is that gender wage gap may be driven by some deep societal features stemming from such basic social codes as language. This suggests that if reducing GWG [gender wage gap, AV] was a policy objective, education on gender equality is needed already at early stages of education, when language characteristics are absorbed by children and translated into societal norms."
Hicks et al. (2015) 'Does mother tongue make for women's work? Linguistics, household labor, and gender identity'; from the abstract: "We use a novel approach relying on linguistic variation and document that households with individuals whose native language emphasizes gender in its grammatical structure are significantly more likely to allocate household tasks on the basis of sex and to do so more intensively."
Davis and Reynolds (2016) 'Gendered language and the educational gender gap'
Shoham et al. (2017) 'Encouraging environmental sustainability through gender: A micro-foundational approach using linguistic gender marking'
Malul et al. (2016) 'Linguistic gender marking gap and female staffing at MNC’s'
Seán Roberts also commented on an earlier paper by some of the authors featured above here. At the bottom of this post he says: "To put it cynically, it’s as if gender inequality is only due to humans being slaves to their language, rather than centuries of active patriarchal societies. The hypothesis doesn’t seem to have a good reason why distinctions in gender should disfavour women over men. Perhaps most disturbing is the authors’ clear appeal for these findings to be used in policy"
Indeed, this is scary stuff.
A more popular paper, albeit with perhaps less dire consequences on policy is Kashima and Kashima (1998), who find a positive correlation between pronoun drop, a grammatical phenomenon where pronouns can be left out of otherwise well-formed sentences, and collectivism, a tendency for society to look after in-group members. As was the case for Santacreu-Vasut et al. (2013), the unit of analysis is the country, with the national language taken to supply information about pronoun drop. This paper has been cited over 300 times and seems to be in high standing in cross-cultural psychological research, as it is being cited in handbooks and otherwise mostly in papers that do not pertain to this exact hypothesis, suggesting it's results are taken as a given. There is also a follow up by the same authors, Kashima and Kashima (2003), including a larger set variables on economy, climate, and geography, and an erratum to the 1998 article from 2005.

This map was made by Gert Jan Hofstede, son of Geert Hofstede, both famous social scientists focusing on cross-cultural differences (see geerthofstede.com)
The established nature of these types of papers is underlined by the fact that the attention to potential spurious correlations is not confined to specialist journals such as Journal of Cross-Cultural Psychology and Applied Economics Letters. Science published a paper in 2014 by Talhelm et al. entitled 'Large-Scale psychological differences within China explained by rice versus wheat agriculture'. From the abstract: "We tested 1162 Han Chinese participants in six sites and found that rice-growing southern China is more interdependent and holistic-thinking than the wheat-growing north." See a popular write-up of the paper here and here.
Luckily, we can count on the absolute hero Seán Roberts to provide a commentary. See here for a blog write-up. Roberts shows that it is very likely that at least part of the correlation reported by Talhelm et al. can be explained by linguistic history, again showing the need for a control for cultural contact and genealogy.
I am sure there are more papers in this vein - please comment if you know of any! I am of half a mind to track them all down, get their data, and show that most if not all of these relations disappear when controlling for genealogical descent and/or diffusion. On the other hand, clearly this would be a waste of time as the premise of most of these papers is that the national or 'most used' language of a country can be of influence on population-level findings on social and economic behaviour, a premise which I think is inherently flawed. The mechanism behind such relationships is simply unfathomable, despite the efforts taken by the authors of these papers to demonstrate the contrary. I am thinking of the level of multilingualism in most countries, let alone the amount of different communities with different psychological and economic behaviours.
Turns out that the paper on rice and wheat agriculture by Talhelm et al. (2014) is in fact an improvement on at least this issue, as it looks in detail at agricultural practices and psychological measures within a set of provinces in one country, China. However, it still doesn't account for the contingencies that arise when comparing communities that are both closely related and in close contact.
There really is no longer any excuse for not incorporating information on geographical distance and genealogical descent in cross-linguistic and cross-cultural analysis. There are reference trees available for all language families in several typological and reference databases (Glottolog, Ethnologue, AUTOTYPE, WALS) - the awesome Dan Dediu has made this extremely easy for you as explained here, as well as Bayesian posterior samples of phylogenetic trees for over 10 language families. On Glottolog, latitude and longitude of the location of a speaker populations are freely available. D-PLACE has cultural variables for many societies around the world linked to language and various phylogenetic trees. All the people that have worked on potentially spurious correlations in language and culture know how to use statistics, well great! - you can use multilevel models and regressions that correct for genealogical relatedness and geographic distance and do things the way you should be doing things.

Vortices, Principia Philosophiae, René Descartes, 1644.
EDIT: Seán Roberts alerted me to the newly published The Palgrave Handbook of Economics and Language, with a paper by Nigel Fabb that is critical of these studies entitled "Linguistic Theory, Linguistic Diversity and Whorfian Economics". His main critiques are 1) the linguistic data is simplified to such an extent that it may no longer represent linguistic facts; and 2) the studies do not present a demonstration of causation despite their claims, and need to present a far more rigourous case both in theory and in experimentation. I am really happy this critical paper was published in a venue which will surely be read by economists, yay!
Selected references
Chen, M. K. (2013). The Effect of Language on Economic Behavior: Evidence from Savings Rates, Health Behaviors, and Retirement Assets. American Economic Review 103.690–731.
Kashima, E. S. & Kashima, Y. (1998). Culture and language: The case of cultural dimensions and personal pronoun use. Journal of Cross-Cultural Psychology 29.461-486.
Kashima, Y. & Kashima, E. S. (2003). Individualism, GNP, climate, and pronoun drop: Is individualsm determined by affluence and climate, or does language play a role? Journal of Cross-Cultural Psychology 34.125-134.
Ladd, D. R., Roberts, S. G. & Dediu, D. (2014). Correlational studies in typological and historical linguistics. Annual Review of Linguistics 1.221-41.
Nichols, J. (1992). Linguistic diversity in space and time. Chicago: University of Chicago Press.
Roberts, S. G. & Winters, J. (2013). Linguistic diversity and traffic accidents: Lessons from statistical studies of cultural traits. PloS One 8.e70902.
Roberts, S. G., Winters, J. & Chen, K. (2015). Future tense and economic decisions: Controlling for cultural evolution. PloS One 10.e0132145.
Santacreu-Vasut, E., Shoham, A. & Gay, V. (2013). Do female/male distinctions in language matter? Evidence from gender political quotas. Applied Economics Letters 20.495-98.

Cool post! There are two more papers I found recently in this worrying trend:
ReplyDeleteShoham & Mook Lee (2017) (same authors as for one of the papers above): A paper on gender marking and wage inequality.
https://www.researchgate.net/publication/314143144_The_Causal_Impact_of_Grammatical_Gender_Marking_on_Gender_Wage_Inequality_and_Country_Income_Inequality?citedPub=272504541
There are no controls for linguistic history as far as I can tell, though the authors argue "Linguistic structures are shown to vary widely across and within families. Thus, grammatical gender structures capture more than geographical or historical forces.". I don't buy this argument.
The paper actually does cite the paper by James and I on spurious correlations, but interprets it as saying that hidden 3rd variables may be mediating the relationships, and so uses a mediation model for the analysis. The method is good and plenty of attention is paid to the kinds of statistical problems that economists care about. But the main results have p-values between 0.05 and 0.01 (and in one case apparently between 0.1 and 0.05), so would probably not survive some historical controls.
The issue of using the 'dominant language' for a country is also a big problem. For example, there are hundreds of languages spoken in Nigeria, but only data from Hausa is used (spoken by only about 20% of the population). It also means that values Arabic is entered as the main language for 19 countries, further extending the non-independencies. Without solving this problem, the data is just not good enough to do the job. Unfortunately, it looks like many papers are using the gender data from Santacreu-Vasut et al. wholesale, probably because they are easily accessible and appear in an economics journal.
It's actually a hard problem, since the economic data are country-level. One of the differences between this and Chen's future tense paper was that the data for the latter came from individual people who listed both their main language and whether they saved money.
The conclusions are at least positive:
"The most important outcome of this research is the understanding that market forces will reduce gender inequality very slowly, if at all, in countries with high gender marking (see the listin Appendix B). In these cases, regulations enforced by policy makers could be very effective. For example, quotas could be imposed requiring female representation on board of directors. An additional policy that could be considered for dealing with the way language generates gender inequality is changing how policy makers (such as government agencies) and corporations communicate, and making a conscious effort to change how language is used in their reports to more female-friendly forms, especially in countries that speak languages with high gender marking, such as Spanish and Arabic. For example, consciously using gender-neutral expressions (“chairperson,” instead of “chairman” or “chair- woman”) might counteract the effect of gender markers in the long run."
But I'm worried that resources could be directed at the wrong targets.
Another paper also looks at gender and wage gaps. It also uses the gender indices in Santacreu-Vasut et al.:
http://www.wne.uw.edu.pl/inf/wyd/WP/WNE_WP138.pdf
This paper has appeared as a 'working paper' online before publication, as did the original gender-marking/economics paper and Keith Chen's future tense paper. It seems to be a common practice in economics, but I wonder if it contributes to the spread of weak methods and data.
Thanks for these two additions Sean! Yes, the country-level data is a hard problem, and in my opinion an insurmountable one. It is impossible to investigate these questions in an insightful way with taking linguistic data from one language per country, as you make very clear with the example from Nigeria.
DeleteAs for the conclusions and recommendations on policy, for me it is just morally wrong to make such claims on an inherently flawed analysis. I actually feel that they are trivializing the issues women face in an unequal world. As you said in one of your posts, it isn't even clear why populations speaking a language with grammatical gender should should treat women worse than men. Clearly this is the cause from the way society and religion has viewed women as less than men for centuries in many places around the world. Blaming it on grammatical gender is just downplaying the unequal reality faced by most women on the globe on a daily basis :(.
But as you say, the way Chen did it for his dataset on saving money, and the way Talhelm et al. did it for their study on rice and wheat agriculture, there are ways to investigate these questions in a useful manner, by taking smaller samples from well-defined communities that have a singular cultural identity including language, and use controls for history and geographical proximity. I hope at some point these investigators will switch to these more appropriate & useful small scale studies.
Just to not forget about the more critical paper by Nigel Fabb, here is the full reference:
DeleteFabb, Nigel. 2016. Linguistic theory, linguistic diversity and whorfian economics. In Victor Ginsburgh & Shlomo Weber (eds.), The Palgrave handbook of economics and language, 17-60. Basingstoke: Palgrave Macmillan.
I couldn't agree more!
ReplyDelete