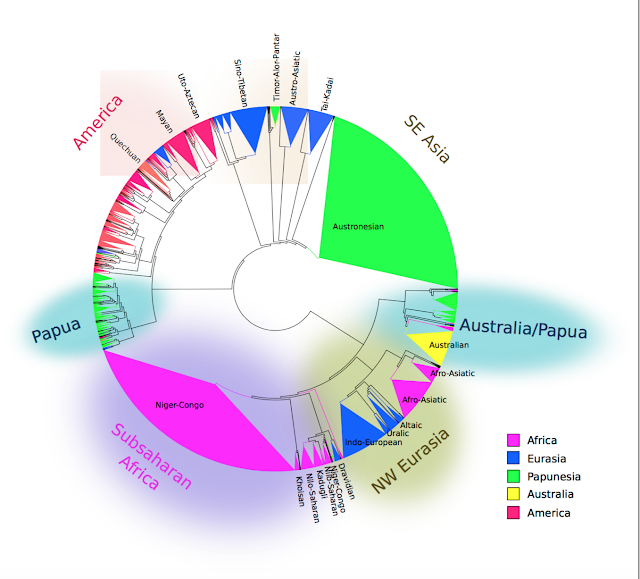
Are these linguistic features of languages really interesting to correlate, or are the similarities muddled by shared family history or contact?
Seán Roberts and James Winters have produced some nice illustrations on the so called Galton's problem in linguistics. This problem, as it applies to linguistic can be formulated like so:
How do we know that a set of features in languages are correlated independently from shared genealogy or contact?
 Some might ask: why is this even a problem? Well, if we are aiming to understand language as the human capacity that we've had for 100 000+ years and all over the world, and all the great diversity that we have and the possible design-space of language (what the limits are for what language can be) - and why the ones we have data on (the living ones today and a few dead ones) cluster the way they do in that design-space: then we'd like to know which variables and data points are dependent and independent, so that we can understand the reality and what is probable to effect it.
Some might ask: why is this even a problem? Well, if we are aiming to understand language as the human capacity that we've had for 100 000+ years and all over the world, and all the great diversity that we have and the possible design-space of language (what the limits are for what language can be) - and why the ones we have data on (the living ones today and a few dead ones) cluster the way they do in that design-space: then we'd like to know which variables and data points are dependent and independent, so that we can understand the reality and what is probable to effect it.
Now, that being said: correlations that are dependent of family or contact are not uninteresting: but if that is the case we'd like to test for that so we know for sure.
They have done several post on spurious correlations (for example number of babies and word order), and in general many very interesting stuff. I would reblog every post they make, but in the interest of not over flooding you I recommend you to just start reading their blog as well.
Here's the blog post, go read it!
There are of course also logically dependent features in datasets that one should always be aware of when handling typologic datasets with lots of features. One such example is the position of polar question particles and the type of marking of polar questions in WALS. I.e. one language cannot be coded for both having no question particles (as dominant marking of polar questions) and then having question final question particles. That just logically just do not work with the way the features are set up. The feature of position of question particles is logically dependent on the existence of polar particles (as the dominant marking strategy, not the only). If we mash up these two features of WALS, we can actually see that there are not violations of this logical dependency.
Now, that being said the WALS and many other databases of typological features are often anthologies of several different surveys by different researchers. Sometimes this can lead to discrepancies. So, if possible try and compare surveys done by the same person(s). This is actually not a problem in WALS actually, what I kan see. The authors generally keep to very different areas that do not overlap enough for this to be a problem.
p.s. if you don't have access to interesting datasets such as those they have been using but would like to play around with correlates, well first of you actually do have access to quite a large set (see list here) but also play with Gap Minder and Google N-Grams. When you're using data form a wide time period, always be aware that the methods and goals of gathering data 200 years ago are not directly comparable with data gathered 3 years ago. The kinds of books published in 1820's are not the same as the kind of books published in 2000's (consider for example Harlequin novels which are a large part of book publication nowadays actually).
How do we know that a set of features in languages are correlated independently from shared genealogy or contact?
Now, that being said: correlations that are dependent of family or contact are not uninteresting: but if that is the case we'd like to test for that so we know for sure.
They have done several post on spurious correlations (for example number of babies and word order), and in general many very interesting stuff. I would reblog every post they make, but in the interest of not over flooding you I recommend you to just start reading their blog as well.
Here's the blog post, go read it!
Now, that being said the WALS and many other databases of typological features are often anthologies of several different surveys by different researchers. Sometimes this can lead to discrepancies. So, if possible try and compare surveys done by the same person(s). This is actually not a problem in WALS actually, what I kan see. The authors generally keep to very different areas that do not overlap enough for this to be a problem.
p.s. if you don't have access to interesting datasets such as those they have been using but would like to play around with correlates, well first of you actually do have access to quite a large set (see list here) but also play with Gap Minder and Google N-Grams. When you're using data form a wide time period, always be aware that the methods and goals of gathering data 200 years ago are not directly comparable with data gathered 3 years ago. The kinds of books published in 1820's are not the same as the kind of books published in 2000's (consider for example Harlequin novels which are a large part of book publication nowadays actually).

Comments
Post a Comment