Workshop on linguistic databases
This week in Nijmegen there was a workshop on cross-linguistic databases, organized by Harald Hammarström and Guillaume Ségerer. Here are some random highlights and thoughts.
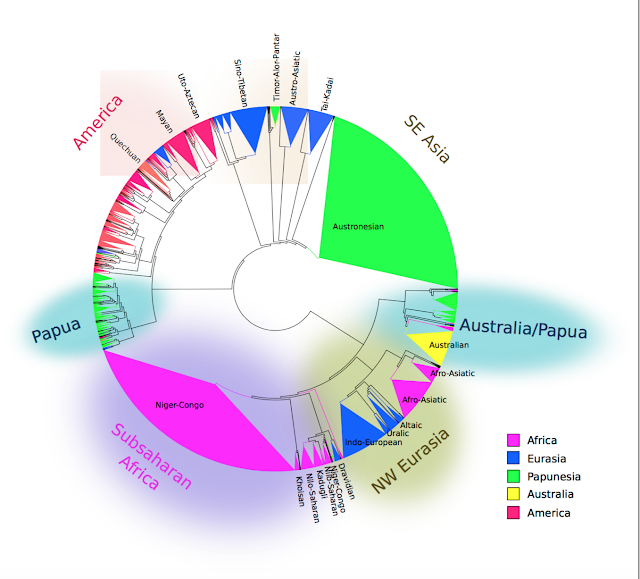
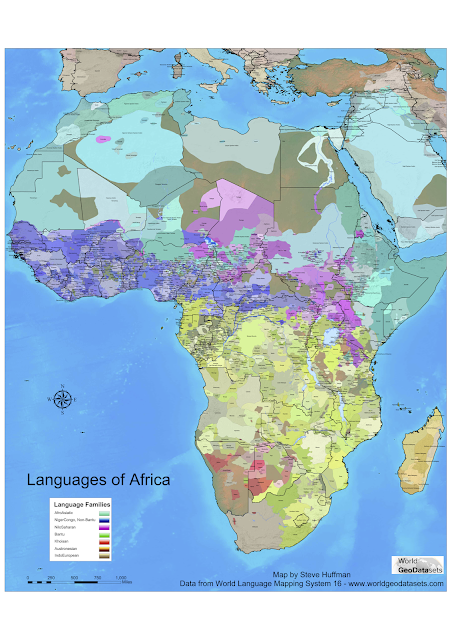
One important application is in testing hypotheses about language history. There were talks on RefLex for reconstructing lexicons of languages in Africa; SAILS for inferring linguistic areas in South America; and the history of Austronesian languages using the World Phonotactics Database.
PHOIBLE, a database of 2160 phonemes/segments and which languages they are found in, has new materials available for download at the PHOIBLE Github such as the decomposition of each phoneme into phonological features. You can search not just for languages with a certain phoneme, but for languages with phonemes defined by a certain set of features (e.g. all types of 't', or all fricatives).
Some semantic databases were shown, including a beautiful visualization tool for showing common cross-linguistic polysemies at CLiCS. Here is an example of the semantic network of the verb 'give', which shares the same form in five languages as the word for 'surrender'. All five of the languages are Uralic. This shows how a semantic pattern has been inherited or shared between these languages. Interestingly, the words for 'give' in these languages are all different, as shown in the top left corner, showing how a semantic pattern can be transmitted independently of the forms themselves.
Paul Heggarty presented his database of pronunciations of different words in English dialects and Germanic languages. The question of how to standardize dialect names (e.g. English spoken in northeastern Scotland) arose. I would like to see data points tied to specific speakers and geographical coordinates, as one possible solution. The time that the data was elicited, and other information about the speaker could be provided (where they were born, gender, age, etc.). Each datapoint could then be referred to as 'Speaker 1, (51.25, 0.04), 09:00 10/10/2014'.
There would then not necessarily be any need to standardize language or dialect names, which just leads to a proliferation of names. A search for British English could just be a search within a set of coordinates or a hand-drawn region on a map; as could a search for English spoken in North London, or English spoken on one side of Wimbledon. This would allow arbitrarily fine-grained analysis of languages - e.g. Wa spoken in the centre of Ximeng (Yunnan, China) uses one form for 'eat', and half an hour's walk down the hill another form is used. There is no need to specify different varieties of Wa just because of this difference; all that is needed is to tie a datapoint for the form 'eat' to a particular location, speaker and time. This would also give you very fine-grained geographic and socio-linguistic data.
Data from different databases can be compared, such as comparing phonological data with semantic, or genetic data with lexicons, and so on. Much of the work in comparing data from different databases is in reconciling different formats. There was therefore a consensus that there should be a standardized format for databases, which is probably a good idea (although Sean Roberts had a vague concern that this would speed up people's ability to fish through databases for spurious correlations). The format in CLLD is a good standard to use. There is also a plan for a website with an overview of all linguistic databases; in the mean time, the database page on this blog provides some of the more accessible ones.
One important application is in testing hypotheses about language history. There were talks on RefLex for reconstructing lexicons of languages in Africa; SAILS for inferring linguistic areas in South America; and the history of Austronesian languages using the World Phonotactics Database.
PHOIBLE, a database of 2160 phonemes/segments and which languages they are found in, has new materials available for download at the PHOIBLE Github such as the decomposition of each phoneme into phonological features. You can search not just for languages with a certain phoneme, but for languages with phonemes defined by a certain set of features (e.g. all types of 't', or all fricatives).
Some semantic databases were shown, including a beautiful visualization tool for showing common cross-linguistic polysemies at CLiCS. Here is an example of the semantic network of the verb 'give', which shares the same form in five languages as the word for 'surrender'. All five of the languages are Uralic. This shows how a semantic pattern has been inherited or shared between these languages. Interestingly, the words for 'give' in these languages are all different, as shown in the top left corner, showing how a semantic pattern can be transmitted independently of the forms themselves.

Paul Heggarty presented his database of pronunciations of different words in English dialects and Germanic languages. The question of how to standardize dialect names (e.g. English spoken in northeastern Scotland) arose. I would like to see data points tied to specific speakers and geographical coordinates, as one possible solution. The time that the data was elicited, and other information about the speaker could be provided (where they were born, gender, age, etc.). Each datapoint could then be referred to as 'Speaker 1, (51.25, 0.04), 09:00 10/10/2014'.
There would then not necessarily be any need to standardize language or dialect names, which just leads to a proliferation of names. A search for British English could just be a search within a set of coordinates or a hand-drawn region on a map; as could a search for English spoken in North London, or English spoken on one side of Wimbledon. This would allow arbitrarily fine-grained analysis of languages - e.g. Wa spoken in the centre of Ximeng (Yunnan, China) uses one form for 'eat', and half an hour's walk down the hill another form is used. There is no need to specify different varieties of Wa just because of this difference; all that is needed is to tie a datapoint for the form 'eat' to a particular location, speaker and time. This would also give you very fine-grained geographic and socio-linguistic data.
Data from different databases can be compared, such as comparing phonological data with semantic, or genetic data with lexicons, and so on. Much of the work in comparing data from different databases is in reconciling different formats. There was therefore a consensus that there should be a standardized format for databases, which is probably a good idea (although Sean Roberts had a vague concern that this would speed up people's ability to fish through databases for spurious correlations). The format in CLLD is a good standard to use. There is also a plan for a website with an overview of all linguistic databases; in the mean time, the database page on this blog provides some of the more accessible ones.

Dang. I was kind of hoping that CLiCS would have some insight on a particular semantic connection I saw in Japanese and Korean. In both languages, the verbs that mean "to listen" and "to be effective, work (for); e.g. medicine" are homophones:
ReplyDeleteKorean: 듣다 (deutda) has both meanings, phonetically identical but separate dictionary entries.
Japanese 聞く (kiku) means 'to listen, hear, ask'; 効く (kiku) means 'to be effective, work (for)'
The words seem extremely unlikely to be Altaic (or sub-Altaic) cognates, but they have the same two meanings (which, to me, seem semantically difficult to reconcile).
Unfortunately, I didn't see anything in CLiCS that connected "listen" or "hear" with "be effective" or anything of the sort, so I don't know whether the correspondence is a coincidence, or the result of a Korean-Japanese sprachbund, or if there are other regional or far-flung languages with the same correspondence (which would make me try harder to determine how they could be semantically related concepts).
Hey Kevin!
ReplyDeleteIsn't it a case of homonymy in Japanese? I'd make the guess that the ki- in 効く is based on a borrowed pronunciation of Chinese 効 xiào. The ki- in 聞くis native Japanese given that it is unrelated to the Chinese 聞 wén. Hence the two kiku's are unrelated within Japanese, one being native vocabulary and the other being Chinese in origin. A homonymy could have travelled somehow by contact into Korean, if for example Japanese speakers of Korean extended one meaning of 듣다 to another on the basis of their two meanings in Japanese. But it seems unlikely. Just my initial guess about what this case is.
I don't believe the kanji are really important in this case, from a long-term historical perspective. The usual Sino-Japanese reading of 効 is kou (こう); if Japanese had constructed a verb based on 効, the usual practice would be for it to be *効す or *効する (which would be *kou-su or *kou-suru). This is one of the cases where I believe the two meanings for an otherwise identical-sounding verb became separated for convenience using different Chinese characters -- this happens all over the place in Japanese, though in most of the cases, the multiple meanings would be more obviously semantically related.
ReplyDelete(Other cases of identical pronuncations with meanings that aren't easily connected: 掛ける (kakeru) 'to hang (transitive)'; 欠ける (kakeru) 'to lack'; 駆ける (kakeru) 'to run'; there is also 賭ける (kakeru) 'to bet (e.g. money)', which Kōjien dictionary connects to the first, 'to hang'; I would agree.)
In fact, Kōjien Japanese Dictionary goes as far as to claim that 効く (which also has an alternative form, 利く) has the same origin as 聞く (that is to say, ignoring the later separate visual representations), but doesn't make a case for how the semantics are connected.
I would agree that the corresponding homonymy could have spread to Korean, or could have spread the other way; but perhaps only if the semantic connection between the two could be made through a common cultural reference, which I haven't run across yet (but maybe I will at some point).
I took a quick tour through Google Translate to see if any of the available languages had identical-sounding words that meant "listen" and "be effective", but out of those on Google Translate, only Japanese and Korean seem to have it.
Another quick note, because I just remembered this one, and it's uncanny:
ReplyDeleteIn Korean, 달리다 (dallida) has three dictionary entries:
1. run, dash, gallop
2. (intrans.) hang (<- note, 'kakeru' in Japanese was transitive)
3. be insufficient, be in short supply (so, intransitive; 'kakeru' for "to lack" has both intransitive and transitive constructions)
So, another phonetically unrelated term with identical but hard-to-reconcile meanings.
Also, somewhat less uncanny:
걸다 (geolda) means '(trans.) to hang'; when money is the object, it also means 'to bet'; in this case, it seems like an obvious sprachbund cultural metaphor.