A decade of state-of-the-art quantitative methods in linguistic typology
Some turning points in linguistic typology are easily recognised, such as the ground-breaking work by Joseph Greenberg on implicational universals entitled "Some universals of grammar with particular reference to the order of meaningful elements" (Greenberg 1963). Other turning points are less well-defined, less commonly associated with a single paper, or a specific typologist, team, or place. But there was definitely something in the water during, let's say, a period centred around 2010 – a change that we could call the quantitative turn in linguistic typology.
Linguistic typologists have long recognised that the languages of the world are related in various ways, most importantly, in nested arrays of hierarchical descent (genealogy) as well as in so-called Sprachbunds or linguistic areas (geography). For a long time, i.e. work reaching from Bell (1978) all the way to Bakker (2010), these interdependencies have been viewed as something of a nuisance, something to get rid of using sampling: Only languages from as many as possible different and independent genealogical and geographical units are included in one's study. Correlations and distributions are then assessed using contingency tables and statistical tests that evaluate differences in counts, most importantly, Fisher's Exact test and Pearson's chi-squared test.
Between 2008 and 2010 or so, something changed. Linguistic typologists started using methods that no longer relied on sampling techniques. (At least) three more advanced quantitative methods for linguistic typology emerged:

I'm not quite sure who first introduced regression models and later, generalized linear mixed-effect models for linguistic typology. Sinnemäki (2010) is certainly one of the first, in his 2011 dissertation he describes how he got the idea of regression modelling from a lecture by Balthasar Bickel in March 2008. Other studies employing regression models that came out around the same time are Cysouw (2010) and Bakker et al. (2011). Good examples of fruitful usage of these methods are Moran et al. (2012), who falsify the idea that there is a positive relationship between population size and phoneme inventory size first proposed by Hay and Bauer (2007), and Atkinson (2011), who proposes a negative relationship between phoneme inventory size and distance from West Africa. The latter paper triggered a lot of replies on the typological and sociolinguistic measures used in linguistic typology and appropriate statistics for evaluating interactions between them.
Out of these three methods, it seems that generalized linear mixed-effect models are now fast becoming the most widely used statistical tool on the typologists' belt, with a flurry of recent (recent meaning 2018/19) papers such as Gast and Koptjevskaja-Tamm (2018), Lester et al. (2018), Schmidtke-Bode & Levshina (2018), Sinnemäki & Di Garbo (2018), Schmidtke-Bode (2019), and Sinnemäki (2019). The most important one of these from a methodological perspective is Coupé (2018), who reports on the recent usage of generalized linear mixed-effect models but goes much further by introducing generalized additive models for location, scale, and shape for linguistic typology.
It's 2020! Palindrome Day has come and gone, and anyway – this year marks the first full decade after the the quantitative turn in linguistic typology. That is, if we want to put down the year 2010 for that – for sure it had been coming on for a few years in 2010, so feel free to argue with me on that. I think that it's absolutely wonderful that these methods are being used and developed further, and I hope to see this this particular element of doing typology flourish in years to come.
I also hope to have made the teeny-tiniest contribution to this flourishing by teaching a one-week course on quantitative methods in typology for LOT last month. We made an overview of pros and cons of these three methods (plus good-old-fashioned sampling) in class – so see below, there's your guide to your method-of-choice, depending how hard-core you want to go (Ben Bolker's GLMM disclaimers are always a nice way to come back down to earth).

References
Linguistic typologists have long recognised that the languages of the world are related in various ways, most importantly, in nested arrays of hierarchical descent (genealogy) as well as in so-called Sprachbunds or linguistic areas (geography). For a long time, i.e. work reaching from Bell (1978) all the way to Bakker (2010), these interdependencies have been viewed as something of a nuisance, something to get rid of using sampling: Only languages from as many as possible different and independent genealogical and geographical units are included in one's study. Correlations and distributions are then assessed using contingency tables and statistical tests that evaluate differences in counts, most importantly, Fisher's Exact test and Pearson's chi-squared test.
Between 2008 and 2010 or so, something changed. Linguistic typologists started using methods that no longer relied on sampling techniques. (At least) three more advanced quantitative methods for linguistic typology emerged:
- The Family Bias method, which estimates statistical biases in distributions of typological variables across and within language families (big families as well as small families, including isolates). The method is set out in Bickel (2013), but also in Bickel (2011) and (2015), and has a long history as an earlier manuscript (Bickel 2008) mentions talks given on the topic already in 2006.
- Generalized linear mixed-effect models (GLMMs) and other regression models. These model a dependent or response variable in terms of independent or predictor variables and are widely used both in linguistics and outside it (Coupé 2018). The benefit for typologists is that there are various ways to include information on genealogy and geography in the analysis, in order to make sure that interdependencies between datapoints are not due to shared history or areality.
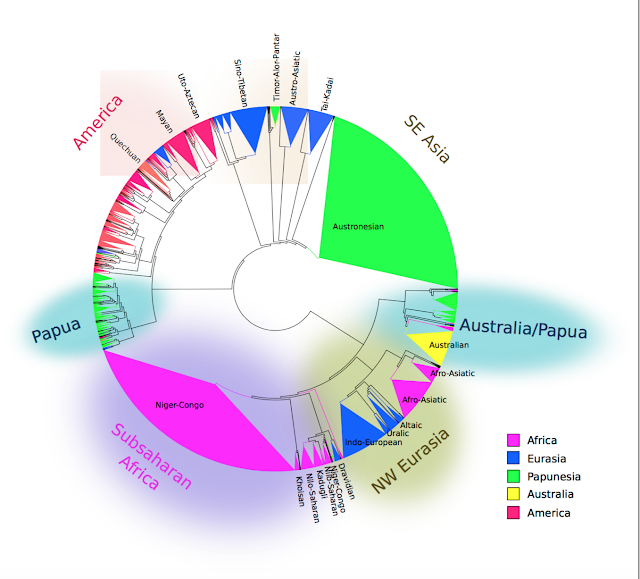
- Phylogenetic comparative methods are a set of tools adopted from evolutionary biology, another discipline which studies the characteristics of entities with long and pertinent histories. These methods model the evolution and distribution of cross-linguistic data on phylogenetic trees. Their first application was Dunn et al. (2011), the famous paper on lineage-specific trends in word order universals.
(c) xkcd
Out of these three methods, it seems that generalized linear mixed-effect models are now fast becoming the most widely used statistical tool on the typologists' belt, with a flurry of recent (recent meaning 2018/19) papers such as Gast and Koptjevskaja-Tamm (2018), Lester et al. (2018), Schmidtke-Bode & Levshina (2018), Sinnemäki & Di Garbo (2018), Schmidtke-Bode (2019), and Sinnemäki (2019). The most important one of these from a methodological perspective is Coupé (2018), who reports on the recent usage of generalized linear mixed-effect models but goes much further by introducing generalized additive models for location, scale, and shape for linguistic typology.
It's 2020! Palindrome Day has come and gone, and anyway – this year marks the first full decade after the the quantitative turn in linguistic typology. That is, if we want to put down the year 2010 for that – for sure it had been coming on for a few years in 2010, so feel free to argue with me on that. I think that it's absolutely wonderful that these methods are being used and developed further, and I hope to see this this particular element of doing typology flourish in years to come.
I also hope to have made the teeny-tiniest contribution to this flourishing by teaching a one-week course on quantitative methods in typology for LOT last month. We made an overview of pros and cons of these three methods (plus good-old-fashioned sampling) in class – so see below, there's your guide to your method-of-choice, depending how hard-core you want to go (Ben Bolker's GLMM disclaimers are always a nice way to come back down to earth).
References
Atkinson, Quentin D. 2011. ‘Phonemic Diversity Supports a Serial Founder Effect Model of Language Expansion from Africa’ Science 332 (6027): 346–349.
Bell, Alan. 1978. ‘Language Samples’. In Universals of Human Languages, Volume 1: Method - Theory, edited by Joseph H. Greenberg, Charles A. Ferguson, and Edith A. Moravcsik, 123–56. Stanford: Stanford University Press.
Bakker, Dik. 2010. ‘Language Sampling’. In The Oxford Handbook of Linguistic Typology, edited by Jae Jung Song. Oxford: Oxford University Press.
Bakker, Peter, Aymeric Daval-Markussen, Mikael Parkvall, and Ingo Plag. 2011. ‘Creoles Are Typologically Distinct from Non-Creoles’. Journal of Pidgin and Creole Languages26 (1): 5–42.
Bickel, Balthasar. 2008. A general method for the statistical evaluation of typological distributions. Manuscript, University of Leipzig.
Bickel, Balthasar. 2011. Statistical modeling of language universals. Linguistic Typology 15. 401–414.
Bickel, Balthasar. 2013. “Distributional Biases in Language Families.” In Language Typology and Historical Contingency: In Honor of Johanna Nichols, edited by Balthasar Bickel, Lenore A. Grenoble, David A. Peterson, and Alan Timberlake, 415–44. Amsterdam: John Benjamins.
Bickel, Balthasar. 2015. “Distributional Typology: Statistical Inquiries into the Dynamics of Linguistic Diversity.” In The Oxford Handbook of Linguistic Analysis, 2nd Edition, edited by Bernd Heine and Heiko Narrog, 901–23. Oxford: Oxford University Press.
Coupé, Christophe. 2018. ‘Modeling Linguistic Variables with Regression Models: Addressing Non-Gaussian Distributions, Non-Independent Observations, and Non-Linear Predictors with Random Effects and Generalized Additive Models for Location, Scale and Shape’. Frontiers in Psychology 9: 513.
Cysouw, Michael. 2010. ‘Dealing with Diversity: Towards an Explanation of NP-Internal Word Order Frequencies’. Linguistic Typology14 (2–3): 221–34.
Dunn, Michael, Simon J. Greenhill, Stephen C. Levinson, and Russell D. Gray. 2011. ‘Evolved Structure of Language Shows Lineage-Specific Trends in Word-Order Universals’. Nature 473 (7345): 79–82.
Gast, Volker, and Maria Koptjevskaja-Tamm. 2018. ‘The Areal Factor in Lexical Typology’. In Aspects of Linguistic Variation, edited by Daniël Olmen, Tanja Mortelmans, and Frank Brisard, 43–82. Berlin, Boston: De Gruyter.
Greenberg, Joseph H. 1963. ‘Some Universals of Grammar with Particular Reference to the Order of Meaningful Elements’. In Universals of Language, edited by Joseph H. Greenberg, 73–113. London: MIT Press.
Hay, Jennifer, and Laurie Bauer. 2007. ‘Phoneme Inventory Size and Population Size’. Language 83 (2): 388–400.
Lester, Nicholas A, Sandra Auderset, and Phillip G. Rogers. 2018. ‘Case Inflection and the Functional Indeterminacy of Nouns: A Cross-Linguistic Analysis’. In Proceedings of the 40th Annual Meeting of the Cognitive Science Society.
Moran, Steven, Daniel McCloy, and Richard Wright. 2012. ‘Revisiting Population Size vs. Phoneme Inventory Size’. Language 88 (4): 877–893.
Schmidtke-Bode, Karsten. 2019. “Attractor States and Diachronic Change in Hawkins’s ‘Processing Typology.’” In Explanation in Typology: Diachronic Sources, Functional Motivations and the Nature of the Evidence, edited by Karsten Schmidtke-Bode, Natalia Levshina, Susanne Maria Michaelis, and Ilja A. Seržant, 123–48. Berlin: Language Science Press.
Schmidtke-Bode, Karsten, and Natalia Levshina. 2018. ‘Reassessing Scale Effects On Differential Case Marking: Methodological, Conceptual And Theoretical Issues In The Quest For A Universal’. In Diachrony of Differential Argument Marking, edited by Ilja A. Seržant and Alena Witzlack-Makarevich, 509–37. Berlin: Language Science Press.
Sinnemäki, Kaius. 2010. ‘Word Order in Zero-Marking Languages’. Studies in Language 34 (4): 869–912.
Sinnemäki, Kaius. 2019. “On the Distribution and Complexity of Gender and Numeral Classifiers.” In Grammatical Gender and Linguistic Complexity: Volume II: World-Wide Comparative Studies, edited by Francesca Di Garbo, Bruno Olsson, and Bernhard Wälchli, 133–200. Berlin: Language Science Press.
Sinnemäki, Kaius, and Francesca Di Garbo. 2018. “Language Structures May Adapt to the Sociolinguistic Environment, but It Matters What and How You Count: A Typological Study of Verbal and Nominal Complexity.” Frontiers in Psychology 9: 89–23.

Comments
Post a Comment