ALT2019 conference report
Two weeks ago, the 13th Conference of the Association for Linguistic Typology (ALT) took place in Pavia, Italy. As the name says, this is the main gathering for members of the Association for Linguistic Typology, and it's on a different continent every two years. It just happened to be in Europe as I was ready to go conferencing again (now dragging two kids in tow) so that was lucky.
I like ALT a lot because I can go to basically any talk and find myself interested in it. There are hardly any talks or posters where I am disappointed because it isn't really my cup of tea - it's all typology so everything is my cup of tea :)! It is where the humans who read grammars gather. This year, ALT was paired with a summer school on 'Language universals and language diversity in an evolutionary perspective', which I would have loved to attend (but, kids).
For the first time in history (as far as we could find), ALT offered child care. About 5 attendees made use of this (and so the next generation of linguists are already networking ;)), in my case it really helped to attend some talks and give our own. Unfortunately I couldn't attend as many talks as I wanted, but as a logistic experiment it was mostly a success. Below I'll feature some talks I attended and others I wanted to attend but didn't, so you can read a bit about the latest & upcoming work in typology.

The first talks I managed to attend where those by Kirsten Culhane ('A typology of consonant/zero alternations') and Erich Round ('Canonical phonology'), both part of the workshop on 'Current research in phonological typology'. Culhane's talk argues for a more typologically informed analysis of consonant insertions and deletions, especially considering phonological and morphological conditions. Round's talk explained in detail why phonologists invariably diverge in their analyses of particular aspects of phonology, and how this can be avoided using a canonical approach.
Later that day, I wanted to attend Denis Creissels' talk on 'Cross-linguistic tendencies in the encoding of experiencers in the languages of Sub-Saharan Africa, and possible typological correlations' but I had to leave because the older kid wouldn't shut up - which several people found very funny.
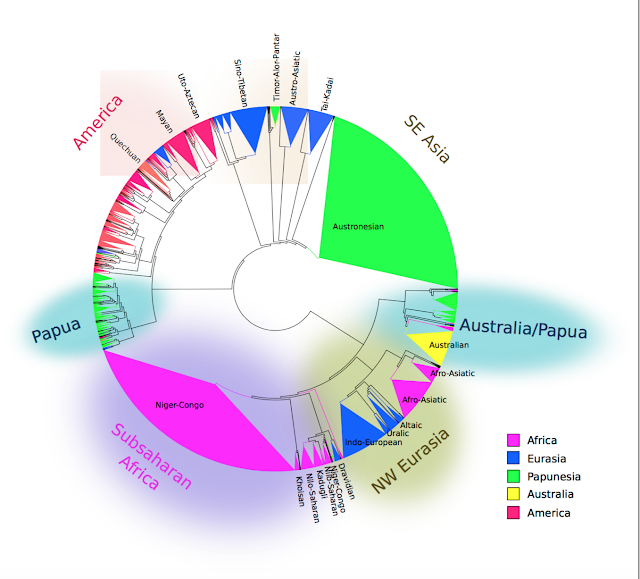
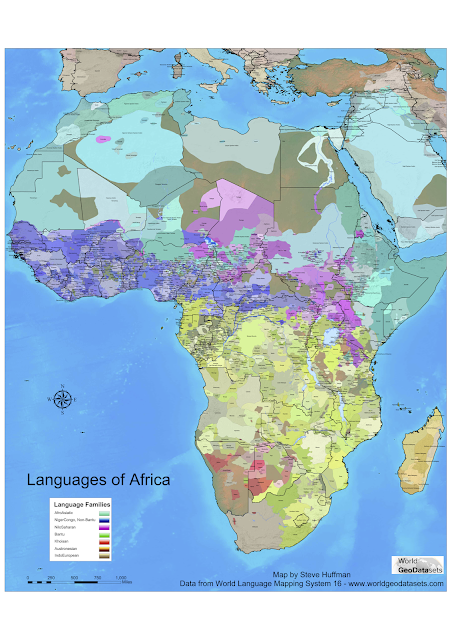
The final day of the conference I was finally able to see some more talks. First, Kilu von Prince et al. ('Realis and irrealis in Oceanic'), who argued how the realis vs. irrealis distinction is relevant in Oceanic and probably also outside it (see here for the slides). Then, Jeff Good et al. with a more methodological talk on 'Individual-based socio-spatial networks as a tool for areal typology'. They presented extremely fine-grained data on language competence of individuals in a highly multilingual region, integrating linguistic, social, and geographic data (see picture below). Then, Dmitry Idiatov and Mark van de Velde ('Single feature approach to linguistic areas: labial-velars and the prehistory of the Macro-Sudan Belt') spoke about how labial-velar stops might be a characteristic of the now disappeared indigenous languages of West and Central Africa, whose speakers have shifted to various Niger-Congo languages.

Then it was time for our own talk ('Testing Greenberg’s universals on a global scale'), which was suffering a bit in attendance because in one of the parallel sessions, Nikolaus Himmelmann was speaking about 'Against trivialising linguistic description, and comparison'. In the abstract he had written 'In fact, Haspelmath’s approach to comparative concepts trivialises crosslinguistic comparison by elevating the pragmatic approach to grammatical comparison apparently required when compiling resources such as the WALS (Dryer & Haspelmath 2013) to the only proper methodology in crosslinguistic comparison. There are other, more rigorous and methodologically superior approaches to comparison, ...' so I guess people went to see what would happen during question time as Martin Haspelmath was attending. I am told there was some interesting discussion.
I missed a lot of cool new talks :(, in alphabetical order:
Chundra Cathcart et al.'s talk on numeral classifiers and plural marking in Indo-Iranian, showing that there is some evidence for the hypothesis that numeral classifiers develop more often in languages without plural marking;
Francesca Di Garbo's talk showing that in Cushitic and beyond, plural agreement can be dependent on lexical-semantic properties of the noun;
Jessica Ivani & Taras Zakharko's presentation of Tymber;
Gerhard Jäger's talk on Differential Object Marking and Differential Subject Marking investigated using hierarchical Bayesian modelling. This can be seen as a follow-up to work by Balthasar Bickel et al. and Karsten Schmidtke-Bode & Natalia Levshina that is interesting to follow because all three author sets use different methods and have different outcomes;
Olga Krasnoukhova & Johan van der Auwera's talk on the diachrony of a rather curious source of standard negation in certain languages;
Natalia Levshina's talk on the range (narrow vs. wide) that basic grammatical relations have and how this range can be investigated using corpora, showing that Finnish is the most extreme 'tight-fit' language, while Chinese and English are the most extreme 'loose-fit';
Ilja Seržant's talk on the lengths of person-number affixes of verbs, finding no evidence for Gívon's cycle (where indexes demise via phonological attrition and new indexes are formed through free personal pronouns);
Manuel Widmer et al.'s talk on the evolution of hierarchical person-marking systems in Tupian and Sino-Tibetan, showcasing the differences and commonalities of these systems in the two families.
Another thing I missed was the business meeting, which was sad because they are usually quite enjoyable - so know I don't know where ALT will be in two years time. If you do, please post a comment! Thanks to all involved for hosting a great conference.

I like ALT a lot because I can go to basically any talk and find myself interested in it. There are hardly any talks or posters where I am disappointed because it isn't really my cup of tea - it's all typology so everything is my cup of tea :)! It is where the humans who read grammars gather. This year, ALT was paired with a summer school on 'Language universals and language diversity in an evolutionary perspective', which I would have loved to attend (but, kids).
For the first time in history (as far as we could find), ALT offered child care. About 5 attendees made use of this (and so the next generation of linguists are already networking ;)), in my case it really helped to attend some talks and give our own. Unfortunately I couldn't attend as many talks as I wanted, but as a logistic experiment it was mostly a success. Below I'll feature some talks I attended and others I wanted to attend but didn't, so you can read a bit about the latest & upcoming work in typology.

The first talks I managed to attend where those by Kirsten Culhane ('A typology of consonant/zero alternations') and Erich Round ('Canonical phonology'), both part of the workshop on 'Current research in phonological typology'. Culhane's talk argues for a more typologically informed analysis of consonant insertions and deletions, especially considering phonological and morphological conditions. Round's talk explained in detail why phonologists invariably diverge in their analyses of particular aspects of phonology, and how this can be avoided using a canonical approach.
Later that day, I wanted to attend Denis Creissels' talk on 'Cross-linguistic tendencies in the encoding of experiencers in the languages of Sub-Saharan Africa, and possible typological correlations' but I had to leave because the older kid wouldn't shut up - which several people found very funny.
The final day of the conference I was finally able to see some more talks. First, Kilu von Prince et al. ('Realis and irrealis in Oceanic'), who argued how the realis vs. irrealis distinction is relevant in Oceanic and probably also outside it (see here for the slides). Then, Jeff Good et al. with a more methodological talk on 'Individual-based socio-spatial networks as a tool for areal typology'. They presented extremely fine-grained data on language competence of individuals in a highly multilingual region, integrating linguistic, social, and geographic data (see picture below). Then, Dmitry Idiatov and Mark van de Velde ('Single feature approach to linguistic areas: labial-velars and the prehistory of the Macro-Sudan Belt') spoke about how labial-velar stops might be a characteristic of the now disappeared indigenous languages of West and Central Africa, whose speakers have shifted to various Niger-Congo languages.

Then it was time for our own talk ('Testing Greenberg’s universals on a global scale'), which was suffering a bit in attendance because in one of the parallel sessions, Nikolaus Himmelmann was speaking about 'Against trivialising linguistic description, and comparison'. In the abstract he had written 'In fact, Haspelmath’s approach to comparative concepts trivialises crosslinguistic comparison by elevating the pragmatic approach to grammatical comparison apparently required when compiling resources such as the WALS (Dryer & Haspelmath 2013) to the only proper methodology in crosslinguistic comparison. There are other, more rigorous and methodologically superior approaches to comparison, ...' so I guess people went to see what would happen during question time as Martin Haspelmath was attending. I am told there was some interesting discussion.
I missed a lot of cool new talks :(, in alphabetical order:
Chundra Cathcart et al.'s talk on numeral classifiers and plural marking in Indo-Iranian, showing that there is some evidence for the hypothesis that numeral classifiers develop more often in languages without plural marking;
Francesca Di Garbo's talk showing that in Cushitic and beyond, plural agreement can be dependent on lexical-semantic properties of the noun;
Jessica Ivani & Taras Zakharko's presentation of Tymber;
Gerhard Jäger's talk on Differential Object Marking and Differential Subject Marking investigated using hierarchical Bayesian modelling. This can be seen as a follow-up to work by Balthasar Bickel et al. and Karsten Schmidtke-Bode & Natalia Levshina that is interesting to follow because all three author sets use different methods and have different outcomes;
Olga Krasnoukhova & Johan van der Auwera's talk on the diachrony of a rather curious source of standard negation in certain languages;
Natalia Levshina's talk on the range (narrow vs. wide) that basic grammatical relations have and how this range can be investigated using corpora, showing that Finnish is the most extreme 'tight-fit' language, while Chinese and English are the most extreme 'loose-fit';
Ilja Seržant's talk on the lengths of person-number affixes of verbs, finding no evidence for Gívon's cycle (where indexes demise via phonological attrition and new indexes are formed through free personal pronouns);
Manuel Widmer et al.'s talk on the evolution of hierarchical person-marking systems in Tupian and Sino-Tibetan, showcasing the differences and commonalities of these systems in the two families.
Another thing I missed was the business meeting, which was sad because they are usually quite enjoyable - so know I don't know where ALT will be in two years time. If you do, please post a comment! Thanks to all involved for hosting a great conference.


Comments
Post a Comment