On the topic of standardising linguistic terminology, pt 2
(Pt1 is a longer text guiding to different resources of linguistic terminology and some of the issues that I bring up here, you can read it here. I continuously update that text, please take care with dates.)
This is a topic that comes up often when one talks to typologists, descriptivists and database-minded
people (and frustrated linguistics students) so I thought I'd get back on it again and share some thoughts.
Recently this topic has been popping up very often for me, I've for example been talking about it with Bettina Klimek of Agile Knowledge Engineering and Semantic Web (AKSW) in Leipzig, and now just recently with Asya Pereltsvaig of Standford and the excellent site Languages of the World. This is an interesting topic to me and very dear to my heart. Having read grammars and tried to fill in typological questionnaires all these issues become much more clear and concrete - it's even one of the reasons we started this blog in the first place. I'm thankful for all the discussions on this topic I've had so far, please share with me your thoughts so that we may advance the discussion further. In the interest of sharing information family, please leave comments on this post on the blog, not on Facebook, Tumblr, twitter etc.
Basically, the issue is this: linguistics is a scientific field that has a lot of terminology that sometimes contradict each other or overlap in non-optimal ways. There's confusion, more in some areas than in others but usually it's extremely hard to find an area that is perfectly free from any terminological controversy. What one author means by "aspect" might not be the same as what another means by this. The major variables that seem to be important, in my personal experience, are
Much of linguistic terminology comes from theoretical linguistics and linguistic typology and is often coloured by a certain framework, survey etc. At the same time as we have this great swarm of terminology, we'd also like to be able to do successful comparative work, and we'd like to be sure that we are indeed comparing like with like. We'd also like to, you know, be able to read each others papers and understand what is going on.
Now, how to get at this? In the natural sciences one strives towards standardisation of terms, perhaps this is also the way to go for linguistics? But what happens when one's study object (people and languages) change constantly and when different angles of analyses can have such huge effects? What happens when we haven't studied them all in enough detail yet? How is such a standard to be created and maintained (cf herding cats)? And finally, what happens if those standardised terms are applied uncritically to languages resulting in a misrepresentation of that language which skews our typology? (This is what I call translation grammars from "typologese" elsewhere.)
I'd like to argue that a strive towards complete universal standardisation of linguistic terms is not only impossible but also destructive to the field. We do indeed need to have certain shared basic assumptions, but for a detailed and pragmatically useful definition that can be realistically applied in a specific study (be it comparative or specific) we must carve out those specifics explicitly every time and always remain critical of previous categories. Otherwise there is a danger that we will only find what we thought to look for and stagnate as a field, and that is sad.
Now, don't get me wrong I don't think that we can expect of every descriptive linguist and every comparativist to take apart every term in its atoms and I do understand and appreciate the need of shared conventions. If we had to define every term all the time we wouldn't have time for anything else. Science is not only about objective discovery, it is also about interaction with other scientists. This requires us to be able to understand each others work, compare, repeat studies etc. In order to interact with the rest of the scientific community we adapt our definitions to some sort of norm, this is natural.
In fact, this is very much how we as linguists believe that speakers/signers of languages behave. In many ways these discussions are not that unsimilar to discussions I sometimes have with language prescriptivists who argue that "well if we are to be as linguistically liberal as you say then everyone would create their own language and no-one would understand each other". The point of language is to communicate (or at least that's one of the points) and the point (or at least one of the points) of science is to interact with each other and by shared knowledge reach higher than any one of us could have reach alone. To accomplish those functions we cannot completely diversify into our own separate islands.
That being said, I believe that language doesn't require the explicit regulation that prescriptivists would like in order to fulfil that function, nor do I believe that linguistics needs an collective enterprise of "once and for all standardising all terms so that we can get something done for once!". As a side note, this was actually kind of the aim of GOLD (Great Ontology of Linguistic Description):
Originally [GOLD] intended to build a single termset that all could use, but this goal was soon seen to be unattainable: there was too much diversity in terms between linguists and sub-communities in linguistics, and considerable reluctance to change them. An ontology, through which these diverse termsets could be linked, thus made the most sense.
Both ends of the spectra are problematic. I've read some descriptions that are full of explicit motivations - but in such foreign framework (for me) that it is extremely hard to get at. I've also read plenty of descriptions with under-defined categories that leave me asking "was this really an article... or was it a determiner.. how can I know?!"
I believe it it possible to strive towards more transparency of the motivations for our analytics choices then is now being made and I do think this will improve our understanding of linguistic diversity. I don't think entirely individualistic term sets are realistic or good, nor do I think one standard is good. Just as I believe that speakers/signers can maintain a norm with shared enough definitions in order to be able to communicate, good enough, so do I believe that linguists can make good linguistics without explicitly defining a norm. The absence of explicit standards encourages people to re-evalutate, discuss and be critical of previous categories, if there was a consensus and standard I believe this would happen less often and that our research would suffer from it.
Please do note that internal systematicity is paramount, be it in descriptive or comparative work. The norms of the large field of linguistics might be dynamic and flexible, but the terms you're applying in your specific research cannot be. This might seem obvious, but it deserves to be said.
If you later would like to go on and compare different descriptions (comparative work) or even compare different typological surveys (levelled up typology) then you do need to work through the definitions, at least the most critical ones for your purpose, and investigate what can be compared directly and what cannot.
As for the overwhelming task of the descriptive linguist, you need not re-invent the wheel just because you are to be explicit about your categories. There are plenty of already existing definitions that one can rely on, the key is 1) to be explicit about the fact that you are using just those and not taking them for granted and 2) be critical when applying them to your specific case. I made a section here on the blog before, that I sometimes update, on the different resources available and some further discussion of these issues.
Now, we can actually do typology without reading grammars and relying on other people's analysis. We can for example do typology via parallel texts (post here) or use tasks and questionnaires designed for gathering data directly from the speakers/signers. Such work has been pioneered at the Max Planck Institute of Psycholinguistics in Nijmegen, you can see some of their stimulus sets and questionnaires here. These kinds of methods actually go all the way back to the foundation of modern typology and Berlin and Kay and their work on the typology of color words, you can see some of it's modern successors here.
Lastly I'd like to bring up a point that I discussed in greater length in the previous post, the issue of keeping comparative and descriptive terms separate. We should not equate terms of description with terms of comparison, the datapoints exist in different systems and therefore have different concerns. A datapoint in a descriptive work mush be true to the material gathered and make sense among the other datapoint of that language, whereas the datapoint in a comparative work must work on the parameter of other languages. They cut up the space differently because of this.
One way of looking at it is that comparative categories are tools and not necessarily "true" entities in themselves (see previous post for overview of Dahl, Bybee and Haspelmath's ideas on this). A standardisation of comparative categories might be more possible and less destructive than standardisation of all terminology, but I don't know what this will gain us really? Stagnation is a danger here too.
So, in closing: we do have shared conventions and norms, this is not weird or bad. These norms are however not to be taken for granted, nor are they enough detailed so that they can be used directly in descriptive or comparative work. In order to do interesting comparative and descriptive work we need more detailed and pragmatically applicable categories. These categories need not, in fact must not, be standardised. If they were standardised we would have problems with stagnation of research. Both ends of the spectra - entirely new terms all the time and complete standard - are bad for our discipline. We need to have more discussions, all of us, on how we should best proceed.
I'd like to, and I can always, write more on this, but I will stop for now. Next time I'll try and recap the Floyd & Haspelmath-debate for some concrete examples of these issues.
This is a topic that comes up often when one talks to typologists, descriptivists and database-minded
people (and frustrated linguistics students) so I thought I'd get back on it again and share some thoughts.
Recently this topic has been popping up very often for me, I've for example been talking about it with Bettina Klimek of Agile Knowledge Engineering and Semantic Web (AKSW) in Leipzig, and now just recently with Asya Pereltsvaig of Standford and the excellent site Languages of the World. This is an interesting topic to me and very dear to my heart. Having read grammars and tried to fill in typological questionnaires all these issues become much more clear and concrete - it's even one of the reasons we started this blog in the first place. I'm thankful for all the discussions on this topic I've had so far, please share with me your thoughts so that we may advance the discussion further. In the interest of sharing information family, please leave comments on this post on the blog, not on Facebook, Tumblr, twitter etc.
Basically, the issue is this: linguistics is a scientific field that has a lot of terminology that sometimes contradict each other or overlap in non-optimal ways. There's confusion, more in some areas than in others but usually it's extremely hard to find an area that is perfectly free from any terminological controversy. What one author means by "aspect" might not be the same as what another means by this. The major variables that seem to be important, in my personal experience, are
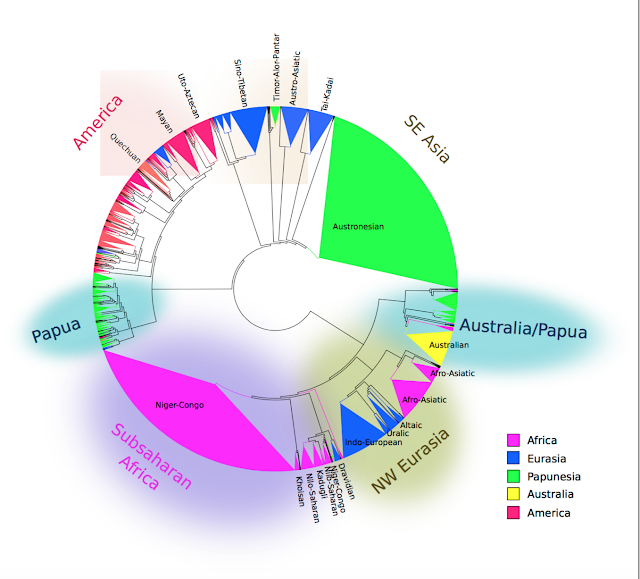
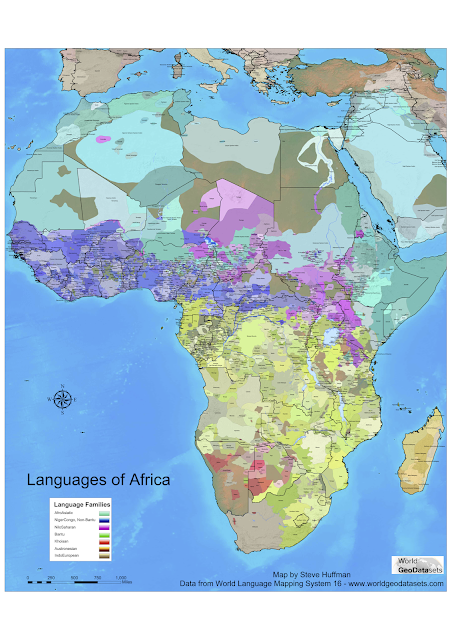
- what language family does the described language belong to?
- what geographical area does the described language belong to?
- was the description in any explicit framework/model/theory?
- when was it written?
- in what language was the description written?
Much of linguistic terminology comes from theoretical linguistics and linguistic typology and is often coloured by a certain framework, survey etc. At the same time as we have this great swarm of terminology, we'd also like to be able to do successful comparative work, and we'd like to be sure that we are indeed comparing like with like. We'd also like to, you know, be able to read each others papers and understand what is going on.
Now, how to get at this? In the natural sciences one strives towards standardisation of terms, perhaps this is also the way to go for linguistics? But what happens when one's study object (people and languages) change constantly and when different angles of analyses can have such huge effects? What happens when we haven't studied them all in enough detail yet? How is such a standard to be created and maintained (cf herding cats)? And finally, what happens if those standardised terms are applied uncritically to languages resulting in a misrepresentation of that language which skews our typology? (This is what I call translation grammars from "typologese" elsewhere.)
I'd like to argue that a strive towards complete universal standardisation of linguistic terms is not only impossible but also destructive to the field. We do indeed need to have certain shared basic assumptions, but for a detailed and pragmatically useful definition that can be realistically applied in a specific study (be it comparative or specific) we must carve out those specifics explicitly every time and always remain critical of previous categories. Otherwise there is a danger that we will only find what we thought to look for and stagnate as a field, and that is sad.
Now, don't get me wrong I don't think that we can expect of every descriptive linguist and every comparativist to take apart every term in its atoms and I do understand and appreciate the need of shared conventions. If we had to define every term all the time we wouldn't have time for anything else. Science is not only about objective discovery, it is also about interaction with other scientists. This requires us to be able to understand each others work, compare, repeat studies etc. In order to interact with the rest of the scientific community we adapt our definitions to some sort of norm, this is natural.
In fact, this is very much how we as linguists believe that speakers/signers of languages behave. In many ways these discussions are not that unsimilar to discussions I sometimes have with language prescriptivists who argue that "well if we are to be as linguistically liberal as you say then everyone would create their own language and no-one would understand each other". The point of language is to communicate (or at least that's one of the points) and the point (or at least one of the points) of science is to interact with each other and by shared knowledge reach higher than any one of us could have reach alone. To accomplish those functions we cannot completely diversify into our own separate islands.
That being said, I believe that language doesn't require the explicit regulation that prescriptivists would like in order to fulfil that function, nor do I believe that linguistics needs an collective enterprise of "once and for all standardising all terms so that we can get something done for once!". As a side note, this was actually kind of the aim of GOLD (Great Ontology of Linguistic Description):
Originally [GOLD] intended to build a single termset that all could use, but this goal was soon seen to be unattainable: there was too much diversity in terms between linguists and sub-communities in linguistics, and considerable reluctance to change them. An ontology, through which these diverse termsets could be linked, thus made the most sense.
Both ends of the spectra are problematic. I've read some descriptions that are full of explicit motivations - but in such foreign framework (for me) that it is extremely hard to get at. I've also read plenty of descriptions with under-defined categories that leave me asking "was this really an article... or was it a determiner.. how can I know?!"
I believe it it possible to strive towards more transparency of the motivations for our analytics choices then is now being made and I do think this will improve our understanding of linguistic diversity. I don't think entirely individualistic term sets are realistic or good, nor do I think one standard is good. Just as I believe that speakers/signers can maintain a norm with shared enough definitions in order to be able to communicate, good enough, so do I believe that linguists can make good linguistics without explicitly defining a norm. The absence of explicit standards encourages people to re-evalutate, discuss and be critical of previous categories, if there was a consensus and standard I believe this would happen less often and that our research would suffer from it.
Please do note that internal systematicity is paramount, be it in descriptive or comparative work. The norms of the large field of linguistics might be dynamic and flexible, but the terms you're applying in your specific research cannot be. This might seem obvious, but it deserves to be said.
If you later would like to go on and compare different descriptions (comparative work) or even compare different typological surveys (levelled up typology) then you do need to work through the definitions, at least the most critical ones for your purpose, and investigate what can be compared directly and what cannot.
As for the overwhelming task of the descriptive linguist, you need not re-invent the wheel just because you are to be explicit about your categories. There are plenty of already existing definitions that one can rely on, the key is 1) to be explicit about the fact that you are using just those and not taking them for granted and 2) be critical when applying them to your specific case. I made a section here on the blog before, that I sometimes update, on the different resources available and some further discussion of these issues.
Now, we can actually do typology without reading grammars and relying on other people's analysis. We can for example do typology via parallel texts (post here) or use tasks and questionnaires designed for gathering data directly from the speakers/signers. Such work has been pioneered at the Max Planck Institute of Psycholinguistics in Nijmegen, you can see some of their stimulus sets and questionnaires here. These kinds of methods actually go all the way back to the foundation of modern typology and Berlin and Kay and their work on the typology of color words, you can see some of it's modern successors here.
Lastly I'd like to bring up a point that I discussed in greater length in the previous post, the issue of keeping comparative and descriptive terms separate. We should not equate terms of description with terms of comparison, the datapoints exist in different systems and therefore have different concerns. A datapoint in a descriptive work mush be true to the material gathered and make sense among the other datapoint of that language, whereas the datapoint in a comparative work must work on the parameter of other languages. They cut up the space differently because of this.
One way of looking at it is that comparative categories are tools and not necessarily "true" entities in themselves (see previous post for overview of Dahl, Bybee and Haspelmath's ideas on this). A standardisation of comparative categories might be more possible and less destructive than standardisation of all terminology, but I don't know what this will gain us really? Stagnation is a danger here too.
So, in closing: we do have shared conventions and norms, this is not weird or bad. These norms are however not to be taken for granted, nor are they enough detailed so that they can be used directly in descriptive or comparative work. In order to do interesting comparative and descriptive work we need more detailed and pragmatically applicable categories. These categories need not, in fact must not, be standardised. If they were standardised we would have problems with stagnation of research. Both ends of the spectra - entirely new terms all the time and complete standard - are bad for our discipline. We need to have more discussions, all of us, on how we should best proceed.
I'd like to, and I can always, write more on this, but I will stop for now. Next time I'll try and recap the Floyd & Haspelmath-debate for some concrete examples of these issues.

Comments
Post a Comment